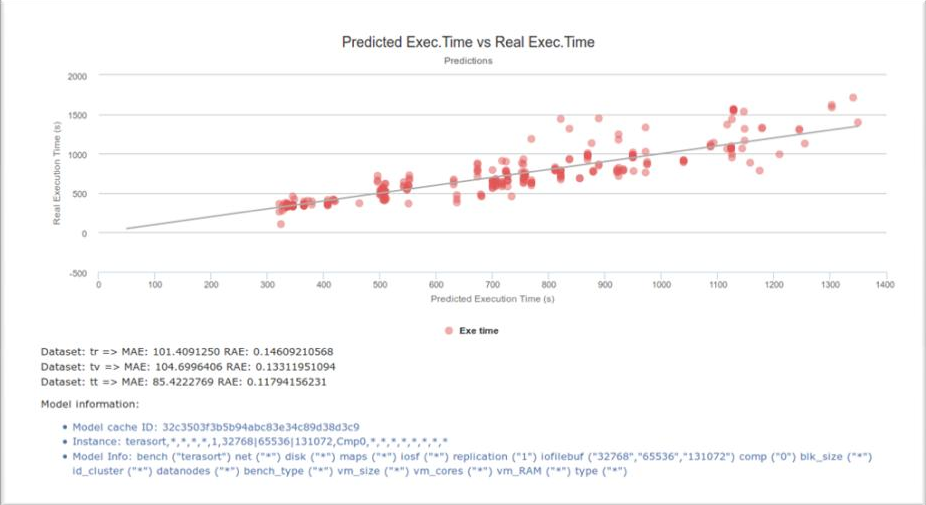
This dataset contains raw traces of Hadoop executions, from configurations to SAR records. Reference: ALOJA paper at IEEE-TETC'17.
| Dataset details: |
| Number of entries |
>50K executions, >800M of records in profiling time series. |
| Notes |
Files contain records of execution results and execution raw traces taken with SAR, VMSTAT and other profiling tools. The full data-set occupies more than 2 TB.
|
| ALOJA Files: |
| HDI_JOB_details |
hdi_job_details_id, id_exec, job_id, bytes_read, bytes_written, committed_heap_bytes, cpu_milliseconds, failed_maps, failed_reduces, failed_shuffle, file_bytes_read, file_bytes_written, file_large_read_ops, file_read_ops, file_write_ops, finished_maps, finish_time, gc_time_millis, job_priority, launch_time, map_input_records, map_output_records, mb_millis_maps, merged_map_outputs, millis_maps, other_local_maps, physical_memory_bytes, slots_millis_maps, spilled_records, split_raw_bytes, submit_time, total_launched_maps, total_maps, total_reduces, user, vcores_millis_maps, virtual_memory_bytes, wasb_bytes_read, wasb_bytes_written, wasb_large_read_ops, wasb_read_ops, wasb_write_ops, job_name, records_written, bad_id, combine_input_records, combine_output_records, connection, io_error, map_output_bytes, map_output_materialized_bytes, mb_millis_reduces, millis_reduces, rack_local_maps, reduce_input_groups, reduce_input_records, reduce_output_records, reduce_shuffle_bytes, wrong_length, wrong_map, wrong_reduce, total_launched_reduces, shuffled_maps, slots_millis_reduces, vcores_millis_reduces, checksum, num_failed_maps, hdfs_bytes_read, hdfs_bytes_written, hdfs_read_ops, hdfs_write_ops, hdfs_large_read_ops, hdfs_large_write_ops, data_local_maps |
| JOB_details |
id_job_details, id_exec, job_name, jobid, jobname, submit_time, launch_time, finish_time, job_priority, user, total_maps, failed_maps, finished_maps, total_reduces, failed_reduces, launched map tasks, rack-local map tasks, launched reduce tasks, slots_millis_maps, slots_millis_reduces, data-local map tasks, file_bytes_written, file_bytes_read, hdfs_bytes_written, hdfs_bytes_read, bytes read, bytes written, spilled records, split_raw_bytes, map input records, map output records, map input bytes, map output bytes, map output materialized bytes, reduce input groups, reduce input records, reduce output records, reduce shuffle bytes, combine input records, combine output records |
| JOB_dbscan |
id, bench, job_offset, metric_x, metric_y, TASK_TYPE, id_exec, centroid_x, centroid_y |
| clusters |
id_cluster, name, cost_hour, type, link, datanodes, headnodes, vm_size, vm_OS, vm_cores, vm_RAM, description, provider, cost_remote, cost_SSD, cost_IB |
| execs |
id_exec, id_cluster, exec, bench, exe_time, start_time, end_time, net, disk, bench_type, maps, iosf, replication, iofilebuf, comp, blk_size, zabbix_link, hadoop_version, valid, filter, outlier, perf_details, exec_type, datasize, scale_factor, JAVA_XMS, JAVA_XMX, run_num |
| hosts |
id_host, host_name, id_cluster, role, cost_remote, cost_SSD, cost_IB |
| precal_cpu_metrics |
id_exec, avg%user, max%user, min%user, stddev_pop%user, var_pop%user, avg%nice, max%nice, min%nice, stddev_pop%nice, var_pop%nice, avg%system, max%system, min%system, stddev_pop%system, var_pop%system, avg%iowait, max%iowait, min%iowait, stddev_pop%iowait, var_pop%iowait, avg%steal, max%steal, min%steal, stddev_pop%steal, var_pop%steal, avg%idle, max%idle, min%idle, stddev_pop%idle, var_pop%idle |
| precal_disk_metrics |
id_exec, DEV, avgtps, maxtps, mintps, avgrd_sec/s, maxrd_sec/s, minrd_sec/s, stddev_poprd_sec/s, var_poprd_sec/s, sumrd_sec/s, avgwr_sec/s, maxwr_sec/s, minwr_sec/s, stddev_popwr_sec/s, var_popwr_sec/s, sumwr_sec/s, avgrq_sz, maxrq_sz, minrq_sz, stddev_poprq_sz, var_poprq_sz, avgqu_sz, maxqu_sz, minqu_sz, stddev_popqu_sz, var_popqu_sz, avgawait, maxawait, minawait, stddev_popawait, var_popawait, avg%util, max%util, min%util, stddev_pop%util, var_pop%util, avgsvctm, maxsvctm, minsvctm, stddev_popsvctm, var_popsvctm |
| precal_memory_metrics |
id_exec, DEV, avgkbmemfree, maxkbmemfree, minkbmemfree, stddev_popkbmemfree, var_popkbmemfree, avgkbmemused, maxkbmemused, minkbmemused, stddev_popkbmemused, var_popkbmemused, avg%memused, max%memused, min%memused, stddev_pop%memused, var_pop%memused, avgkbbuffers, maxkbbuffers, minkbbuffers, stddev_popkbbuffers, var_popkbbuffers, avgkbcached, maxkbcached, minkbcached, stddev_popkbcached, var_popkbcached, avgkbcommit, maxkbcommit, minkbcommit, stddev_popkbcommit, var_popkbcommit, avg%commit, max%commit, min%commit, stddev_pop%commit, var_pop%commit, avgkbactive, maxkbactive, minkbactive, stddev_popkbactive, var_popkbactive, avgkbinact, maxkbinact, minkbinact, stddev_popkbinact, var_popkbinact |
| precal_network_metrics |
id_exec, IFACE, avgrxpck/s, maxrxpck/s, minrxpck/s, stddev_poprxpck/s, var_poprxpck/s, sumrxpck/s, avgtxpck/s, maxtxpck/s, mintxpck/s, stddev_poptxpck/s, var_poptxpck/s, sumtxpck/s, avgrxkB/s, maxrxkB/s, minrxkB/s, stddev_poprxkB/s, var_poprxkB/s, sumrxkB/s, avgtxkB/s, maxtxkB/s, mintxkB/s, stddev_poptxkB/s, var_poptxkB/s, sumtxkB/s, avgrxcmp/s, maxrxcmp/s, minrxcmp/s, stddev_poprxcmp/s, var_poprxcmp/s, sumrxcmp/s, avgtxcmp/s, maxtxcmp/s, mintxcmp/s, stddev_poptxcmp/s, var_poptxcmp/s, sumtxcmp/s, avgrxmcst/s, maxrxmcst/s, minrxmcst/s, stddev_poprxmcst/s, var_poprxmcst/s, sumrxmcst/s |
| ALOJA_logs Files: |
| BWM |
id_BWM, id_exec, host, unix_timestamp, iface_name, bytes_out, bytes_in, bytes_total, packets_out, packets_in, packets_total, errors_out, errors_in |
BWM2
|
id_BWM, id_exec, host, unix_timestamp, iface_name, bytes_out/s, bytes_in/s, bytes_total/s, bytes_in, bytes_out, packets_out/s, packets_in/s, packets_total/s, packets_in, packets_out, errors_out/s, errors_in/s, errors_in, errors_out |
| HDI_JOB_tasks |
hdi_job_task_id, job_id, task_id, bytes_read, bytes_written, committed_heap_bytes, cpu_milliseconds, failed_shuffle, file_bytes_read, file_bytes_written, file_read_ops, file_write_ops, gc_time_millis, map_input_records, map_output_records, merged_map_outputs, physical_memory_bytes, spilled_records, split_raw_bytes, task_error, task_finish_time, task_start_time, task_status, task_type, virtual_memory_bytes, wasb_bytes_read, wasb_bytes_written, wasb_large_read_ops, wasb_read_ops, wasb_write_ops, file_large_read_ops, records_written, map_output_bytes, map_output_materialized_bytes, combine_input_records, combine_output_records, id_exec, reduce_input_groups, reduce_output_groups, reduce_shuffle_bytes, reduce_input_records, reduce_output_records, shuffled_maps, bad_id, io_error, wrong_length, connection, wrong_map, wrong_reduce, checksum, num_failed_maps, hdfs_bytes_read, hdfs_bytes_written, hdfs_large_read_ops, hdfs_large_write_ops, hdfs_read_ops, hdfs_write_ops, job_name, created_files, deserialize_errors, failed_reduces, finished_maps, job_priority, launch_time, mb_millis_maps, mb_millis_reduces, millis_maps, millis_reduces, num_killed_maps, num_killed_reduces, other_local_maps, rack_local_maps, records_in, records_out_intermediate, skewjoinfollowupjobs, slots_millis_maps, slots_millis_reduces, submit_time, total_launched_maps, total_launched_reduces, total_maps, total_reduces, user, vcores_millis_maps, vcores_millis_reduces, data_local_maps |
| JOB_status |
id_job_job_status, id_exec, job_name, jobid, date, maps, shuffle, merge, reduce, waste |
| JOB_tasks |
id_job_job_tasks, id_exec, job_name, jobid, taskid, task_type, task_status, start_time, finish_time, shuffle_time, sort_time, bytes read, bytes written, file_bytes_written, file_bytes_read, hdfs_bytes_written, hdfs_bytes_read, spilled records, split_raw_bytes, map input records, map output records, map input bytes, map output bytes, map output materialized bytes, reduce input groups, reduce input records, reduce output records, reduce shuffle bytes, combine input records, combine output records |
| SAR_block_devices |
id_SAR_block_devices, id_exec, host, interval, date, DEV, tps, rd_sec/s, wr_sec/s, avgrq-sz, avgqu-sz, await, svctm, %util |
| SAR_cpu |
id_SAR_cpu, id_exec, host, interval, date, CPU, %user, %nice, %system, %iowait, %steal, %idle |
| SAR_interrupts |
id_SAR_interrupts, id_exec, host, interval, date, INTR, intr/s" |
| SAR_io_paging |
id_SAR_io_paging, id_exec, host, interval, date, pgpgin/s, pgpgout/s, fault/s, majflt/s, pgfree/s, pgscank/s, pgscand/s, pgsteal/s, %vmeff |
| SAR_io_rate |
id_SAR_io_rate, id_exec, host, interval, date, tps, rtps, wtps, bread/s, bwrtn/s |
| SAR_load |
id_SAR_load, id_exec, host, interval, date, runq-sz, plist-sz, ldavg-1, ldavg-5, ldavg-15, blocked |
| SAR_memory |
id_SAR_memory, id_exec, host, interval, date, frmpg/s, bufpg/s, campg/s |
| SAR_memory_util |
id_SAR_memory_util, id_exec, host, interval, date, kbmemfree, kbmemused, %memused, kbbuffers, kbcached, kbcommit, %commit, kbactive, kbinact, kbdirty |
| SAR_net_devices |
id_SAR_net_devices, id_exec, host, interval, date, IFACE, rxpck/s, txpck/s, rxkB/s, txkB/s, rxcmp/s, txcmp/s, rxmcst/s, %ifutil |
| SAR_net_errors |
id_SAR_net_errors, id_exec, host, interval, date, IFACE, rxerr/s, txerr/s, coll/s, rxdrop/s, txdrop/s, txcarr/s, rxfram/s, rxfifo/s, txfifo/s |
| SAR_net_sockets |
id_SAR_net_sockets, id_exec, host, interval, date, totsck, tcpsck, udpsck, rawsck, ip-frag, tcp-tw |
| SAR_swap |
id_SAR_swap, id_exec, host, interval, date, kbswpfree, kbswpused, %swpused, kbswpcad, %swpcad |
| SAR_swap_util |
id_SAR_swap_util, id_exec, host, interval, date, pswpin/s, pswpout/s |
| SAR_switches |
id_SAR_switches, id_exec, host, interval, date, proc/s, cswch/s |
| VMSTATS |
id_VMSTATS, id_exec, host, time, r, b, swpd, free, buff, cache, si, so, bi, bo, in, cs, us, sy, id, wa, st |